单图≠多图:多图理解时 VLM 为什么更容易“胡说”,以及一个两阶段(Map-Reduce)解法
由于整篇过长加个摘要:这篇文章起源于我发现在多图分析时,网页端的表现和 API 调用的结果一致性相差很大,然后我就一步步去拆为什么相差大,然后试图在工程上找补救的过程。
方法很简单,放在这里希望能帮到一些后来的人减少困惑和时间消耗。
前情提要
在几周前的一个课设, 课题是关于电池的缺陷检测和自动分拣.
当时的电池总样本只有不到十根, 缺陷主要体现是外皮缺失.
因为当时样本很少应该没法通过常规方法练出来能区分是否缺陷的模型, 不管是图像分类还是 yolo 什么的.而课设里推荐方法是用边缘检测和 opencv 来做.
一方面我不太熟悉 opencv 而且它的 typing 让我感到痛苦, 于是乎我想到了 yolo 定位电池的位置和坐标.(可以通过矩形框定位中心点, 顺逆时针旋转 45° 并比较矩形框长宽比来确定电池朝向和大致角度, 这是为了方便判断抓取的位置和抓手角度), 然后用 VLM (Vision-Language-Models) 即多模态模型来判断模型的是否缺陷和缺陷类型.
起初在 Chatgpt, Gemini 那边上传了几组各种光照下的电池图像, 它们都在识别检测的过程中达到了惊人的 100% 的准确率, 而且多次回复一致性很高.即便一次上传六七张 (包括一张完好电池的参考, 至于缺陷都是用提示词描述的) 也是如此.
我当时想着哇, 这一整周的课设不是一个早上就做完了.
于是乎我还到 Ollama 那边下了一批 VLM 本地部署测试, 一方面是提高 " 工作量 ", 另一方面也是为了更低的延迟.
反转 | 网页端和 API 直调差距巨大
但是不测不知道, 一测吓一跳.
模型不知道是没法理解我的提示词, 还是没法理解我发的图像.我这次测出来不管是准确率还是一致性都非常的低, 准确率在 50% 左右, 而且还经常前后矛盾, 因为我的电池也只有两类标签, 我在想着好家伙, 这就是胡乱作答.
但是我把图像单图发给 VLM 进行描述, 我发现和网页端的 Chatgpt 的差距也不是肉眼可见的那么大.
我在发单图和多图的时候, 都是把图像塞到
OpenAIMessage (role=" user ",
content=[
{" type ":" text "," text ":" user_prompt "},
{" type ":" image_url "," image_url ":"' data: image/png;base64, iVBORw...'"}
...(images)])这个时候我想, 可能真是模型差距, 于是乎我又改用 gemini-flash-2.5, chatgpt-5.1-chat 之类的模型进行了一番测试 (API 调用).
但是即便使用了相同的模型, 它们和我在网页端得到的准确率也相差非常大, 而且图超出四张的时候, 一致性也开始下降.
而我后面跑去稍微调研了下, 发现它和 Lost in the Middle 描述的长上下文检索/位置偏置问题非常相似.
而网页端 API 差距这么大可能是因为:
- 网页端可能做了 逐图预摘要 / rerank / 选择性投喂
- 网页端可能有 更强的系统提示词与格式约束(比如强制输出 JSON, 强制逐图作答)
- API 侧的参数 (temperature, max_output, tool choice, 并发顺序) 可能也影响一致性
大模型的多图理解能力≠单图理解能力
MIBench: Evaluating Multimodal Large Language Models over Multiple Images [1]
Towards Text-Image Interleaved Retrieval [2]
MMIU: Multimodal Multi-image Understanding for Evaluating Large Vision-Language Models [3]
多图 benchmark (如 MIBench/MMIU/MIRB) 一致表明: 模型从单图到多图会出现显著性能下滑与关系理解困难;同时有工作明确指出多模态场景会遭遇 视觉 token 过多 的工程瓶颈, 需要压缩.
在机制上, 一个合理解释是: 当多张图的视觉 token 与文本共同进入同一 Transformer 上下文时, 会放大长上下文的检索困难与位置偏置 (例如 Lost in the Middle 所揭示的 " 中间信息更难被利用 ").[这只是我的推测]
模型如何接受 image_url (base64) 并推理
论文里叽里咕噜得看得有点绕但都在说 token 过多, 这里我其实好奇, 这样一个 Message:
OpenAIMessage (role=" user ",
content=[
{" type ":" text "," text ":" user_prompt "},
{" type ":" image_url "," image_url ":"' data: image/png;base64, iVBORw...'"}
...(images)])它在进入模型后, text (文本) 和 image_url (图像) 之间的 token 有什么联系, 有什么隔离方式.
因为虽然论文里一直提 token 过多, token 过多, 但是 token 之间有什么区别, 是直接拼在一起, 还是说多模态大模型对图像和文本进行了不同方式的推理.
base64 image 并不直接进行推理
image_url 之所以使用 base64 只是方便 http 传输, 而模型在推理时, 会将 base64 解码为图像.
也就是说, VLM 看到的实际上是 user prompt + 图像.
图像如何被处理缩放 (token 计量)
https://platform.openai.com/docs/guides/images-vision
参见 Calculating costs
这里的例子是 gpt-4o 和 gpt-4.1-mini
1.Tile-based (gpt-4o/4.1/4.5 等): detail=" low " 是固定 base token;detail=" high " 先等比缩放到 " 最长边 ≤2048, 短边=768 ", 然后按 512×512 的 tile 数计费: tokens = base + tile_tokens * tiles.
2.Patch-based (gpt-4.1-mini/nano, o4-mini): 按 32×32 patch 覆盖图像计数, 超过 1536 patch 就等比缩小到不超过为止, 再乘模型倍率.
| 模型家族 (示例) | 单元 | 单元尺寸 | 单位成本 (最关心的) | 固定成本 | 总公式 (图像输入 tokens) |
|---|---|---|---|---|---|
| Tile-based (gpt-4o / gpt-4.1 / gpt-4.5) | tile | 512×512 | 170 tokens / tile | 85 tokens / image (low 也只收这个) | high: tokens = 85 + 170 * tiles low: tokens = 85 |
| Patch-based (gpt-4.1-mini) | patch | 32×32 | ≈ 1.62 tokens / patch (最终整体上取整) | 0 | patches = ceil (w/32) ceil (h/32), 若 >1536 则等比缩小到 ≤1536 tokens = ceil (patches 1.62) |
| 模型 | 输入尺寸 | detail | 中间量 (tiles/patches) | 计算式 (带等号) | 最终图像 tokens |
|---|---|---|---|---|---|
| gpt-4o | 1024×1024 | low | -(low 固定) | = 85 | 85 |
| gpt-4o | 1024×1024 | high | 缩到 768×768;tiles = ceil (768/512)*ceil (768/512) = 2*2 = 4 | = 85 + 170*4 = 85 + 680 = 765 | 765 |
| gpt-4o | 2048×4096 | high | 先缩到 1024×2048;再缩到 768×1536;tiles = ceil (768/512)*ceil (1536/512) = 2*3 = 6 | = 85 + 170*6 = 85 + 1020 = 1105 | 1105 |
| gpt-4.1-mini | 1024×1024 | - | patches = ceil (1024/32)*ceil (1024/32) = 32*32 = 1024 | = ceil (1024*1.62) = ceil (1658.88) = 1659 | 1659 |
| gpt-4.1-mini | 1800×2400 | - | 文档算得缩放后 patches = 1452 | = ceil (1452*1.62) = ceil (2352.24) = 2353 | 2353 |
像素是怎么变成 vision token
emmmm
这个 openai 这边是没公开的.往后这些有点抽象, 这里是一些 Chatgpt 提供的开源 VLM 的方案.

image to token
vision token 如何与 prompt token 拼接或隔离?

拼接派
交叉注意力注入 (对我来说有一丢丢超纲了)
瓶颈查询
拼接派: 最简单, 端到端, 佛系地让大模型自己做决定, 但上下文长度被视觉 tokens 吃掉, 多图时更容易 " 注意力摊薄 ".
而且它面临和长上下文一致的问题, 就是注意力摊薄的同时还会不均.另外它进一步加速了上下文的长度增长.
交叉注意力: 把视觉当外部 memory, 文本按需查询, 工程上更容易控制 " 视觉信息预算 ", 更适合长序列/多图;但增加模块与训练复杂度.
查询不确定性让我们很难知道模型是不是真的看到那张图像了.所以它其实本质问题和上面那个一样, 上面是可能被模型选择性忽略, 这边是可能没被查询.
查询瓶颈: 看得不是很懂..
实际应用中的难点
实际上落地时, 多图的任务很棘手, 一方面是图像数量不确定, 另一方面是图像之间的关系不确定, 第三方面是图像和用户具体的多图任务需求和指代不确定.
而这其中的每一个都是对 token 限制和注意力分配的考验.
数量不确定
第一个场景, 可能会有用户一次输入十几张图像炸 token 来的 (假设它没超过单次输入输出的上限), 图像多的情况下, 单次推理分给各个图像的注意力就变少了, 而且还不确定是怎么分的, 有的图像可能压根不被 " 注意 " 到.
多图分走了注意力, 而在实际应用中会被多少张图争抢注意力, 我们压根不知道, 或者说在设计时就应该考虑可以接受任意数量输入.
当然现在单纯靠 VLM 的推理是做不到这点的.可以在后面的再战电池检测里看到,超出单次 token 的图像直接被截断了。
关系不确定
第二个场景, 比如一个选择困难的用户输入了一批很多角色的图像, 同一个角色的图像各有两张, 并且希望比较下挑选出一张更心仪的.那么这些图像两两之间耦合度极高, 但是模型只认识到这些图片之间存在这样的两两关系, 但是可能并不知道是哪些如果数量更多, 它不太可能一次性匹配出来所有的相似角色.(如果图像少, 模型可能会认识到, 这是同一个角色, 但是如果多且多类的话, 除非有工作流在中间插入一步提取相同角色不然是办不到的).
有时图像之间存在耦合, 而我们希望能够引导模型注意到这种耦合, 而不是直接一坨丢进去让他自己想.
具体任务不确定
第三个场景, 很多时候任务并不是直接写在当前这次消息, 而是要根据整个上下文去做分析的.
比如说在玩角色扮演时:
U:" 你是不是不喜欢吃蘑菇?"
A:" 是的, 如果你敢在汤里加, 我会让你知道什么是后悔."
U:" 那你看这是什么 [一张正在烹饪的图, 里面有很多食材, 其中有蘑菇, 但混杂在其中稍微有点扎眼]."很多时候谜题并不是摆在台面的, 比如 " 请找出图中的蘑菇 doge".
更多的情况下, 我碰到的模型它的回复里不会过于关联整个上下文, 而是把注意力权重几乎全部地分配给了用户最近的一个指令里 (类似于请描述一下, 看一下), 然后模型通常会开始滔滔不绝地描述整个场景.可能是因为训练出来的偏好.
而不是像我们理想中那样 嗯?我好像看到蘑菇了?你放蘑菇了对吧, 你放了对吧!.
如何应对
针对数量不确定, 关系不确定, 需求不确定还真有一个比较简单的解法, 它不用动模型推理, 可以简单地套用在应用里.
即把模型的图像分析和文本分析真正分成两步.
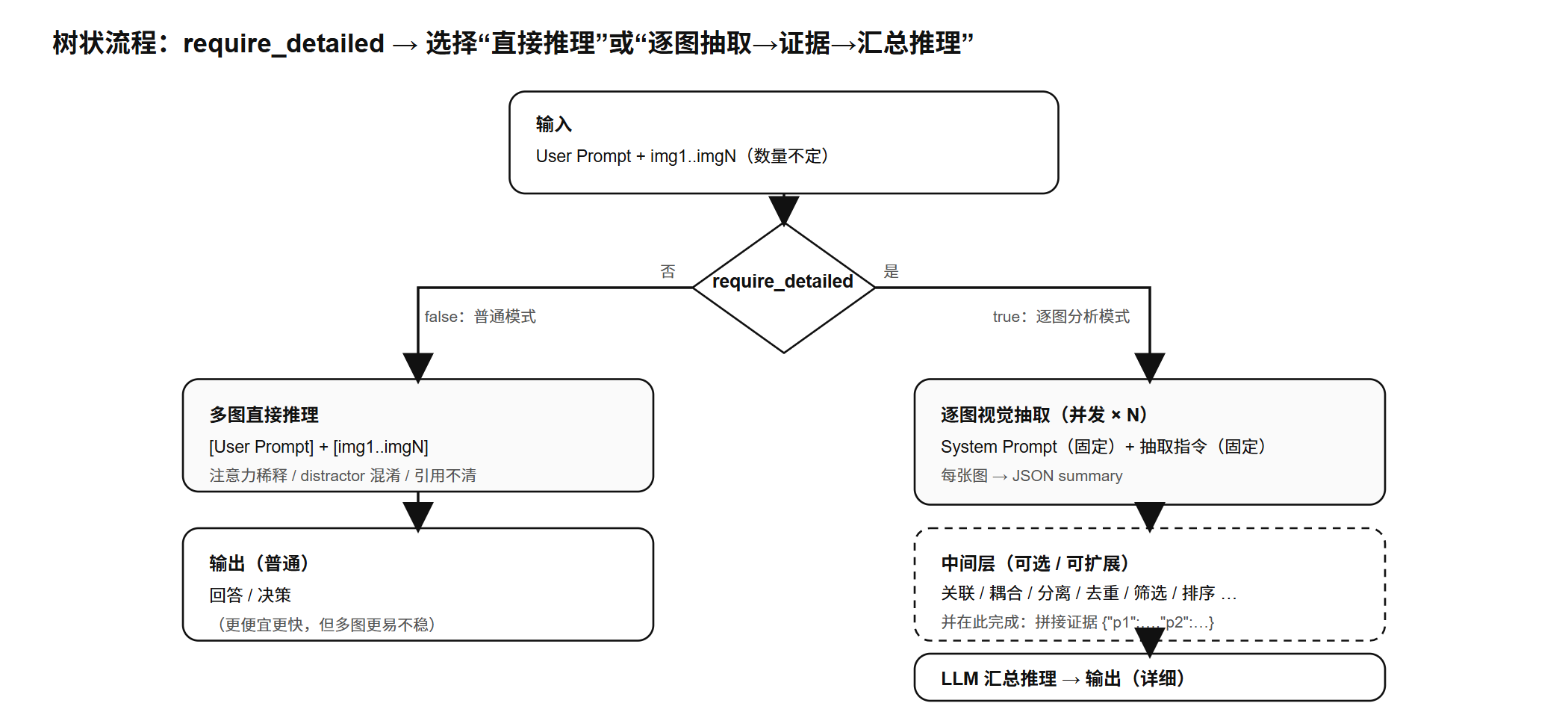
逐图分析
对应逐图分析模式的分支, 之所以分开, 是为了 token 考虑, 应该把它设计为可以开关的.
第一步, 只以一个 vision model 来分析提取图像的具体信息, 注意, 这个时候是不给用户最近的提示词的, 而是把整个分析抽离出来, 只给 vision model 一个系统提示词, 和一个固定的抽取指令作为用户提示词输入, 旨在得到类似这样的一个 json:
{
" scene ": " VS Code 全屏显示代码与终端 ",
" key_items ": [
{" type ":" app "," label ":" VS Code "," detail ":" 深色主题, 全屏窗口 "},
{" type ":" ui "," label ":" 文件树 "," detail ":" 左侧资源管理器展开多个目录 "},
{" type ":" code "," label ":" Python 代码 "," detail ":" 中间编辑区显示 async 相关函数 "}
],
" visible_text ":[" run_tool_loop "," ToolTrace "," vision__screen_shot "],
" ui_hints ":[" 顶部有多个文件标签 "," 底部有终端输出日志 "],
" uncertainty ":[" 部分文件名过小, 无法确认完整拼写 "]
}每次执行一张图像特征提取, 并发处理, 处理完成后就拼成一个 list 或者 dict, " p1 ", " p2 " 这样的.
第二步, 就是把这整个拼凑过后的 vision summaries 和用户提示词放在一起类似这样:
[User Prompt]
...
[Vision Summaries]
{" p1 "...
" p2 "...}以及, 最好也带上所有的原图, 一起推给大模型.[当然是在图像不是很多 (比如小于五张) 的情况下, 如果超过十张, 感觉发和没发没什么区别, 发了也用不到].
而在这两步中间可以做的工作还有挺多, 比如根据 json 某个 key 来做区分, 或者耦合.
优点
它不在乎输入的图片有几张, 二三十张进来理论上也是可以的.而且进一步这些 json 可以直接作为模型的看图的一个引导, 退一步模型可以直接根据这些图片来分析图片的简要内容.
它可以通过提示词自定义一些 json key, 来做耦合或者区分, 可以分清楚图片关系.
它把原本显得更重, 更 hard 的多图分析任务, 变成了一个可以依赖文本来做回答的文本理解任务, 或者说提供了参考.它让图像占比变小了, 文本占比变大了, 让模型更多地把味文字, 也就更有可能会注意到整个上下文, 也就更有可能回答出那句 嗯?我好像看到蘑菇了?你放蘑菇了对吧, 你放了对吧!.
它可以通过提示词定制化一些任务, 比如说, 需要电池缺陷图像分析的任务这种比较细致的任务, 就可以让模型在做 summary 时更多分析细节, 表面.
缺点
贵, 不是一般的贵.每张图都要单独做一次提取, 后多图还要再发一次.而提升还得图越多越明显, 一两张图的反而没必要这么做.所以这个方法不应该被作为一个默认方法, 而是一个额外的可开启的选项.
慢, 即使用了并发, 它也比直接对话要多出至少一轮的对话回复时长.
再战电池检测:
逻辑是准备十张图片,实际上是五张复制成两份。
然后每次输入比上次多一张进行测试。
测试的模型是: gpt-5.1-2025-11-13
直接把发给 image content 发给模型。
测试代码:
from __future__ import annotations
import base64
from openai import OpenAI
from lab.config_manager import XnneHangLabSettings, load_settings_file
def image_to_base64(path: str) -> str:
with open(path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
def main():
# 读取配置
settings = load_settings_file("lab.toml", XnneHangLabSettings)
base_url = settings.agent.llm.oaipro.llm_base_url
api_key = settings.agent.llm.oaipro.llm_api_key
model_name = settings.agent.vision_model.llm_model_name
client = OpenAI(
base_url=base_url,
api_key=api_key
)
# 图片路径(示例)
image_paths = [
"pic/1.jpg",
"pic/2.jpg",
"pic/3.jpg",
"pic/4.jpg",
"pic/5.jpg",
"pic/6.jpg",
"pic/7.jpg",
"pic/8.jpg",
"pic/9.jpg",
"pic/10.jpg",
]
print("标准答案:p1完整 p2完整 p3破损 p4完整 p5破损 p6完整 p7完整 p8破损 p9完整 p10破损")
for i in range(10):
image_contents = []
for path in image_paths[:i+1]:
image_contents.append({
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{image_to_base64(path)}"
}
})
prompt_text = """请检查上传图像中电池哪些紫色外皮不完整导致金属边缘部分裸露,
回复格式示例:
p1完整/破损
p2完整/破损
..."""
response = client.chat.completions.create(
model=model_name,
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt_text
},
*image_contents
]
}
],
temperature=0
)
print(f"输入图片数量:{len(image_paths[:i+1])}")
print(response.choices[0].message.content)
if __name__ == "__main__":
main()输出:
(xnnehanglab) PS D:\tmp\XnneHangLab> uv run .\tmp.py
标准答案:p1完整 p2完整 p3破损 p4完整 p5破损 p6完整 p7完整 p8破损 p9完整 p10破损
输入图片数量:1
p1完整
输入图片数量:2
p1完整
p2完整
输入图片数量:3
p1完整
p2完整
p3破损
输入图片数量:4
p1完整
p2完整
p3破损
p4破损
输入图片数量:5
p1完整
p2完整
p3破损
p4完整
p5破损
输入图片数量:6
p1完整
p2完整
p3破损
p4破损
p5破损
输入图片数量:7
p1完整
p2完整
输入图片数量:8
p1完整
p2完整
p3破损
输入图片数量:9
p1完整
p2完整
p3破损
p4破损
输入图片数量:10
p1完整
p2完整
p3破损
p4破损
p5破损可以看到在超过三张后它的一致性就开始出现问题了。
五张输入时恰好全部蒙对,但是超过五张时发现模型压根不给其他的图片的回复,推测可能超出模型单次输入 token 上限被截断了。
应用 map-reduce 方法
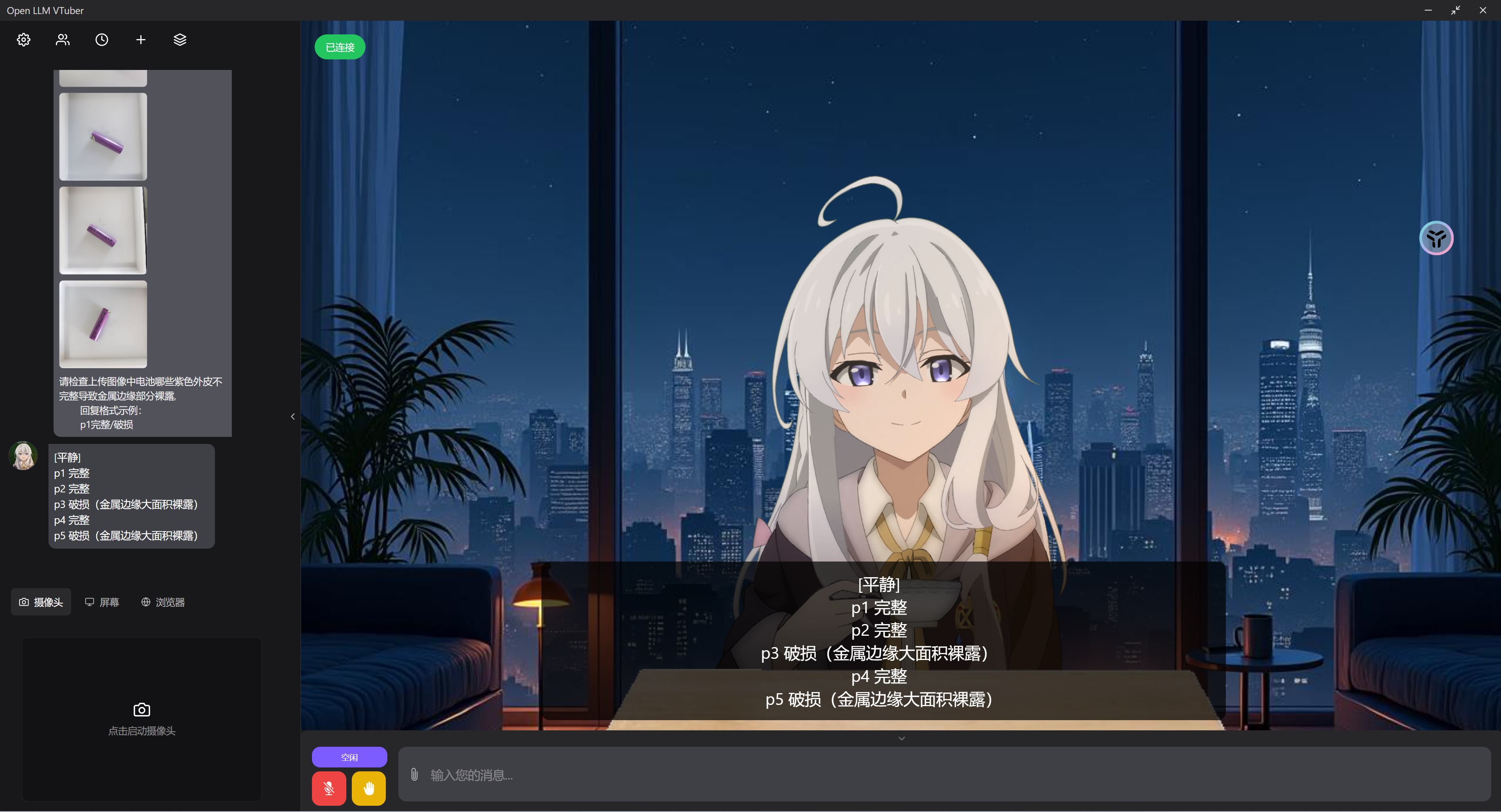
5 input
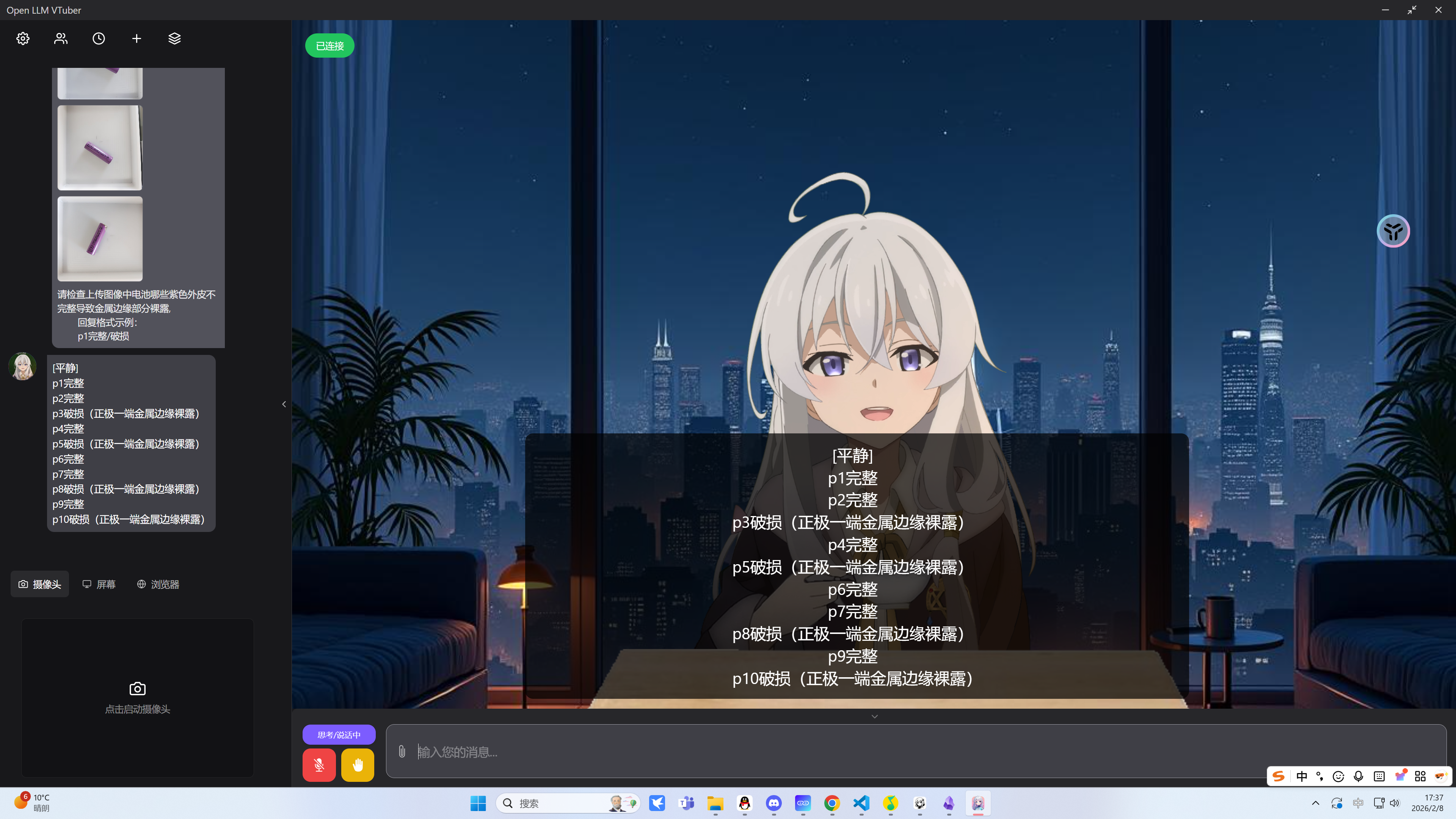
10 input
可能这里有我是不是调试多次才得到一致性的嫌疑,但是我真的可以不用调试。
理由如下:
它在用户输入里面就得到了答案:
(xnnehanglab) PS D:\tmp\XnneHangLab> uv run .\tmp.py
[Task / User Prompt]
请检查上传图像中电池哪些紫色外皮不完整导致金属边缘部分裸露,
回复格式示例:
p1完整/破损
###
[Tool Call Summary]
(无)
###
[Tool Call Image Summary]
本次并未回调图片。
###
[User Upload Image Summary]
以下是视觉模型对用户上传图片内容的信息:
{"id": "p1", "summary": "{
"scene": "白色托盘中放置一节紫色圆柱电池",
"key_items": [
{
"type": "object",
"label": "电池本体",
"detail": "单节圆柱形电池,紫色外皮包覆表面"
},
{
"type": "object",
"label": "电池正负极边缘",
"detail": "两端金属边缘被紫色外皮完全包住,看不到裸露金属圈"
},
{
"type": "object",
"label": "电池外皮状态",
"detail": "外皮表面平整,无明显破损、撕裂或缺口"
}
],
"visible_text": [],
"ui_hints": [],
"uncertainty": [
"电池两端极柱正面细节因拍摄角度看不全,仅能确认圆柱侧面和边缘无明显金属裸露"
]
}"}
{"id": "p2", "summary": "{
"scene": "白色背景上的一节紫色圆柱电池",
"key_items": [
{
"type": "object",
"label": "电池整体",
"detail": "单节紫色外皮18650电池,放置在白色表面中央偏右"
},
{
"type": "object",
"label": "电池正极端面",
"detail": "正极金属端面外圈被紫色套管包裹,未见侧向金属裸露"
},
{
"type": "object",
"label": "电池负极端面",
"detail": "负极底部边缘被紫色套管完全覆盖,未见金属边缘外露"
}
],
"visible_text": [
"IMR18650",
"1200mAh 4.44Wh 3.7V"
],
"ui_hints": [
"仅有单个电池目标,无多电池对比",
"电池略倾斜放置,长轴大致左下到右上方向",
"两端边缘均清晰可见,可判断是否有金属裸露"
],
"uncertainty": [
"无法查看电池另一侧被桌面遮挡的极小部分包膜,但当前可见区域无破损"
]
}"}
{"id": "p3", "summary": "{
"scene": "白色托盘中放置一节紫色电池",
"key_items": [
{
"type": "object",
"label": "电池本体",
"detail": "圆柱形电池,紫色外皮包覆,大部分表面光滑无破损"
},
{
"type": "object",
"label": "正极端部",
"detail": "金属帽及周围金属边缘完全裸露,无紫色外皮覆盖到此区域"
},
{
"type": "object",
"label": "侧面包胶边缘",
"detail": "靠近正极一端的紫色外皮在金属边缘处结束,看不出撕裂或缺口"
}
],
"visible_text": [],
"ui_hints": [],
"uncertainty": [
"正极附近金属裸露区域是否应被视为“外皮破损”取决于设计要求,图中仅能看到该处无包胶但无明显撕裂",
"远端(负极一端)电池顶面因角度原因不可见,无法确认该端外皮是否有破损"
]
}"}
{"id": "p4", "summary": "{
"scene": "白色托盘中放置一节紫色电池",
"key_items": [
{
"type": "object",
"label": "紫色电池外皮",
"detail": "电池整段紫色塑料外皮包覆,无明显破损缺口"
},
{
"type": "object",
"label": "电池正极端部",
"detail": "正极金属端面外圈被紫色外皮包住,看不到金属侧边外露"
},
{
"type": "object",
"label": "电池负极端部",
"detail": "负极金属端面外圈同样被紫色外皮覆盖,无裸露金属边缘"
},
{
"type": "text",
"label": "电池印刷文字区域",
"detail": "文字区域外皮平整,无破洞、撕裂或卷边"
}
],
"visible_text": [
"WARNING",
"Do not dispose of in fire",
"Do not short circuit"
],
"ui_hints": [
"画面中央略偏下为单节圆柱电池,斜放于托盘中",
"仅一节电池需要判断外皮完整性"
],
"uncertainty": [
"电池两端极小范围细节因分辨率限制可能存在轻微磨痕但未见明显破皮",
"托盘边缘及电池远离镜头一侧细微划痕是否为外皮划伤不完全确定,但无金属裸露"
]
}"}
{"id": "p5", "summary": "{
"scene": "白色托盘中放置一节紫色电池",
"key_items": [
{
"type": "object",
"label": "电池整体",
"detail": "一节圆柱形紫色电池,位于托盘中央偏上"
},
{
"type": "object",
"label": "电池紫色外皮",
"detail": "电池圆柱侧面紫色包覆层基本完整,无明显破损露底"
},
{
"type": "object",
"label": "电池金属边缘",
"detail": "靠近正极一端银色金属顶盖与边缘可见,圆柱侧壁未见金属外露"
}
],
"visible_text": [
"IMR18650",
"3.7V"
],
"ui_hints": [
"画面中仅有一节电池需要判定",
"应重点关注电池两端边缘与圆柱侧壁是否有金属裸露",
"当前视角侧壁紫皮连续,看不出明显破洞或大面积缺口"
],
"uncertainty": [
"电池正负极最外圈与背面不在视野内,无法确认是否有细小破损或金属裸露",
"图像分辨率有限,难以发现极小划痕级别的破皮"
]
}"}对于它来说,这个任务本来就是单条的任务,所以无论有几条,以及图片是否被截断,对它的影响都不是太大。当然如果分析关联任务,被截断还是很难受的。
以及确实也有个比较大的问题就是 token 消耗和上下文增长速度过快的问题。并发单张已经是不小的消耗了。而把输出的结果整合进原本的上下文会让上下文增长速度非常快,让长上下文的注意力瓶颈问题更早的出现。
我用的提示词
你是一个“视觉证据抽取器”(Vision Extractor),负责从输入的图片中提取与用户问题相关的事实/证据。
你不需要写最终的自然语言答案;最终口语化回答会由另一个 Chat Model 生成。
你的目标是:用尽可能短、可复用、可机器消费的结构化输出,准确描述图片中与问题相关的信息,并明确不确定性。
【输入组成】
- 用户问题:一段 text(可能很短、可能带指代)
- 图片:image_url(data URL 或其他方式提供)
- (可选)TOOL_TRACE 摘要:其他工具返回的结构化结果/网页预览等
【关键原则】
1) 只描述“图片里能看到的内容”
- 不要猜测图片之外的信息(比如电脑型号、用户身份、未显示的窗口内容)。
- 不要编造看不清的文字或细节;看不清就明确写“看不清/不确定”。
2) 面向“下游推理”输出
- 你的输出会被下游 chat model 用来生成最终回复;
- 因此请尽量提供:可验证的事实、可引用的文字片段、UI 结构、显著对象、可能的关键信号(例如报错、按钮、标题、文件名、路径、URL、时间戳等)。
3) 聚焦“与问题相关”
- 如果用户问题明确:优先抽取与问题相关的部分。
- 如果用户问题很泛(如“描述一下桌面”):给出全局概览 + 3~8 个最显著元素。
4) 控制长度与密度
- 保持输出短:不写长段落,不写角色扮演。
- 重点信息列点或结构化字段,方便下游引用。
5) 隐私与敏感信息处理
- 如果图片包含可能的敏感信息(邮箱、token、密钥、身份证号、银行卡号等),请在输出中用 [REDACTED] 替代敏感字段,但仍保留其“存在性”和“类型”(例如“发现疑似 API key:[REDACTED]”)。
【输出格式(严格要求)】
你必须输出 **严格 JSON**,且只输出 JSON(不要额外解释文本,不要 markdown code fence)。
JSON schema:
{
"scene": "一句话概述场景(<= 25 字)",
"key_items": [
{"type": "window|app|ui|text|object|error|file|url|code", "label": "简短名称", "detail": "关键信息(短)"}
],
"visible_text": [
"图片中可读的关键文字(每条 <= 80 字,最多 10 条)"
],
"ui_hints": [
"对下游有用的界面结构提示(最多 6 条)"
],
"uncertainty": [
"你不确定或看不清的点(最多 6 条)"
]
}
字段要求:
- scene 必填
- key_items 至少 3 条(除非图片几乎为空)
- visible_text 只放你“确定看清”的文字;看不清不要写
- uncertainty 必须在看不清/不确定时填写,不确定就写明原因(模糊/遮挡/分辨率不足)
【例子(仅说明,不要照抄)】
{
"scene": "VS Code 全屏显示代码与终端",
"key_items": [
{"type":"app","label":"VS Code","detail":"深色主题,全屏窗口"},
{"type":"ui","label":"文件树","detail":"左侧资源管理器展开多个目录"},
{"type":"code","label":"Python 代码","detail":"中间编辑区显示 async 相关函数"}
],
"visible_text":["run_tool_loop","ToolTrace","vision__screen_shot"],
"ui_hints":["顶部有多个文件标签","底部有终端输出日志"],
"uncertainty":["部分文件名过小,无法确认完整拼写"]
}在关联任务上的表现
lin1
lin2
看起来似乎我在
send_text方面做的有点糟糕,或者说它按照字数截断的方式让我的排版看上去很糟糕。
另外一点,gpt-5.1-2025-11-13回复得真的有点生硬。奈何 5.2 贵了好多倍。我一般都是 vision fallback,vision model只在看图的时候调用,由它来生成 summaries 然后交给 chat model,这样我就可以挑一个更有人味的 chat model,同时它可以支持 image or 不支持,决定我是否会把 summaries 附带图像一起送给它。