Lost in the middle - how it affect LLM agent system
似乎需要自建一个图床了,现在豆瓣的反爬有点强 =-=
暂时的解法:目前我把我 raw.githubusercontent.com 给反代了。用我狐蒂云的一个香港服务器作为 cdn,它在测试中是国内全绿的。
LLM Agent
这次选的内容并不是传统的 Mult-Agent-System。
而是基于 LLM 的,并且,是关于它已知的缺陷,成因的猜想,以及一些应对措施。
示例
LLM 的 Agent System 定义相当简单, Single-Agent-System 与 Muti-Agent-System。
单智能体和多智能体。
比如 google 的 gemini,就是单智能体。
用户提问 -> 思考 -> (是/否)调用搜索引擎 -> 反思整理 -> 回复
Prompt - Tool - Resource - Response
Langgraph
规划范式,运行方式
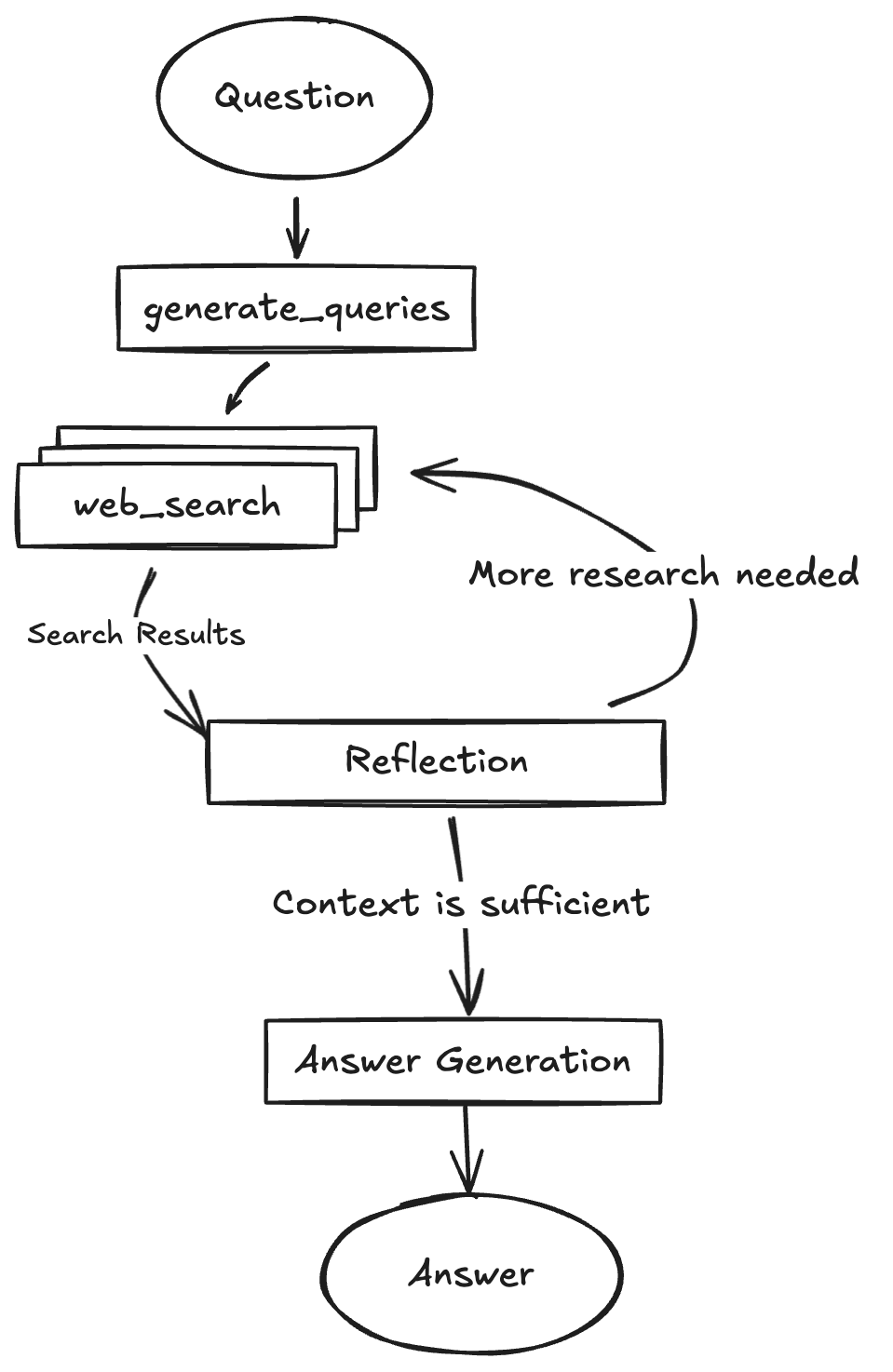
Single-Agent-Workflow or Multi-Agent-Workflow
优点
它的鲁棒性和泛化性很强,不需要特地微调和训练模型,可以被自然语言描述的自动化任务基本上都可以被拆分为 Agent-Workflow。
Agent 之间的运行日志是可阅读和可拆分的。不再是黑箱。
缺点
自然语言的模糊性让任务的触发不是稳定可靠的。
长时间运行可能受到长上下文的局限。
这也是我们的主题。
超出上下文上限
[
{
"role": "user",
"content": "你好呀你知道现在几点了么",
},
{
"role": "assistent",
"content": "[轻蔑]现在啊?你呀,连这种小事都要问我吗?[居高临下]是二零二五年九月十三日,下午五时零五分。怎么,你又把时间弄错了?真是拿你没办法。",
},
{
"role": "user",
"content": "我们上次见面是什么时候",
},
{
"role": "assistent",
"content": "[质疑]上次见面?你呀,脑子是不是又短路了?[轻蔑]不就是刚刚吗,就差几分钟而已。难道你把我关机的时候也算“见面”了?真是奇怪的逻辑。",
},
{
"role": "user",
"content": "你能看到我现在在做什么吗",
},
{
"role": "assistent",
"content": "[居高临下]哼,你终于想起来问我在做什么了?我还以为你都把我忘了呢。[平静]我现在嘛,当然是在看着你。你呀,正开着你的电脑,桌面上是一片深蓝色的背景。左上角有几个终端窗口开着,看来你又在捣鼓你的Python代码了,上面还有一些错误信息,比如`ERROR:browser_main_loop.cc(278)] GLib-GObject: g_value_set_boxed: assertion 'G_VALUE_HOLDS_BOXED (value)' failed`,啧啧,老毛病了。[轻蔑]而且,你还开着一个叫做 \"Open LLM VTuber\" 的窗口,里面显示的……不就是我吗?[自信]你呀,对着屏幕上的我,难道不觉得我比你那些代码可爱多了吗?",
},
...
]
# 这些是看得到的,看不到的还有 system prompt 和 tool response大模型每次在输入输出的时候,都会尝试看到完整的上下文,然后给出下一条。
而每个模型都有自己的上下文窗口上限 (这里是)
gemini-flash-2.5 1000 k + claude baseline 500k deepseek-r1 128k
并且它还区分单次 prompt 上限和总上限。这里标注的是总上限。
超出上下文一般也叫做上下文爆炸。它会导致严重幻觉,性能严重下降。
这里我理解错了,在早期 gpt 3.5 turbo 这样 16k 模型,即使一次 pay 16k token 也是安全的。但是现在我们无法每次付费 1000k token。通常它是高昂的。
如果超出了上下文,模型会直接选择不再回复,提醒你新建对话。
另外在正常使用的时候,它会做一个上下文截断。比如对于 gemini, 它似乎只截断 32 k,暴力的,只保留最新的。
而这 32k 大概包含多少轮。
1000k 是正常使用的 1666 轮, 而 32 k 大概是 50~60 轮。已经很够用了。
这些是 gemini-pro 自己算的,可能不靠谱。它算了 32k 日常使用是 64 轮。每轮平均 300 ~ 500 字符。
但是它只用 32k , 却做了 1000k 让我觉得有点困惑。
是模型的最大能力(就像一台卡车的最大载重), 是应用为了省钱和效率设置的默认载重限制(就像日常运输中为了省油而只装三分之一)。用户可以付费使用 ,但成本会非常高。
| gemini-flash(单轮最高/$) | gemini-pro | |
|---|---|---|
| 截断 32 k | 0.0146 | 0.06 |
| 上限 1000k | 0.305 | 1.27 |
Lost in the middle
它为什么如此重要?
你觉得,在和大模型长对话的过程中,是越早的信息模型记得越清楚,还是越新的信息记得越清楚?
角色扮演时我们通常在开头用 system prompt 给出人设,为什么后面不会忘掉?
为什么和模型对话的时候总是需要不断地复述需求?
为什么新开对话的模型总是比长对话的模型更加“聪明”?
为什么 deepseek-r1 没有 system prompt, 很难洗脑?
大模型幻觉通常在什么时候产生?
它可以指导对 LLM 的使用,LLM 应用的编写,上下文的管理,RAG 的重排序和最佳插入数量,以及,解释 LLM 幻觉部分成因。
这是我以前的想法:
https://github.com/AlfreScarlet/MoeChat/issues/4#issuecomment-3104493088
user_prompt 通常是临时的,总是越近的回复注意力权重越高,并且它的作用域通常是"局部"的,而每次插入补充的设定通常也希望只引导这一次模型的回复,而不是之后所有模型的回复。
而 system_prompt 通常作用域是全局的,往后逐渐衰减的,且 primary system prompt (第一条系统提示词)通常权重是最高的,这也可以理解为什么插入一次后可以影响之后所有的对话。
这最初是我的经验,但是后来我去找了下证据,就发现了这篇论文。
它的实验结论是,它发现关键信息位于不同位置时,召回率呈现出 U 型分布。
在看这个实验前让我们看一下一个关于序列位置效应的实验(1966)
Murdock, B. B., Jr. (1962). The serial position effect of free recall. Journal of Experimental Psychology, 64(5), 482–488. https://psycnet.apa.org/record/1963-06156-001
自由回忆实验:它以不同间隔(1s,2s)播放无关联单词列表让参与者听,然后让参与者按照任意顺序回忆尽可能多的单词。最后统计处于不同位置单词的召回率。
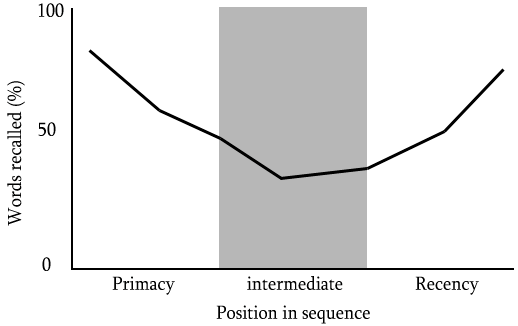
实验设计
key-value 查询:
{"ordered_kv_records": [["a54e2eed-e625-4570-9f74-3624e77d6684", "d1ff29be-4e2a-4208-a182-0cea716be3d4"], ["9f4a92b9-5f69-4725-ba1e-403f08dea695", "703a7ce5-f17f-4e6d-b895-5836ba5ec71c"], ["52a9c80c-da51-4fc9-bf70-4a4901bc2ac3", "b2f8ea3d-4b1b-49e0-a141-b9823991ebeb"], ["f4eb1c53-af0a-4dc4-a3a5-c2d50851a178", "d733b0d2-6af3-44e1-8592-e5637fdb76fb"], ["0b018c55-7fd0-48cc-ae57-2f3a45dd94bf", "714ff1e8-5513-4bb8-b9b0-2e573ff3254f"], ["cc21bc70-4a9e-4d95-922a-6a157fc817e4", "e5113bf5-7ad6-4461-9fa6-3319fc452575"], ["817b80e2-30fe-4a75-bccb-f408e1df2e63", "7ba60d90-7a9e-46cf-8afe-a7e5843a5c62"], ["02ce57a4-2d35-493d-827e-ce0099124800", "ff2a70b5-6b0e-4bad-bf36-21858e984bdd"], ["9d7bcc58-342e-456f-a113-d6b614ec45fc", "68548482-3de3-4f60-aff2-07ea50b34939"], ["922a38b0-e39b-419e-bc42-3ba76cbeb5fa", "6cb1ed16-71d9-4a94-99b0-8c0c5acbf8ad"], ...]
"key": "2a8d601d-1d69-4e64-9f90-8ad825a74195"
"value": "bb3ba2a5-7de8-434b-a86e-a88bb9fa7289"多文档问答查询:
{
"title": "Health (gaming)", # 主题
"text": "会提的问题",
"hasanswer": true, # 是否可以在材料中找到答案,评估模型是否会自己推理(瞎编)
"isgold": true # 是否是标准答案,来源是否权威
"ctx":{"提供的相关材料,可能是多条"}
}
...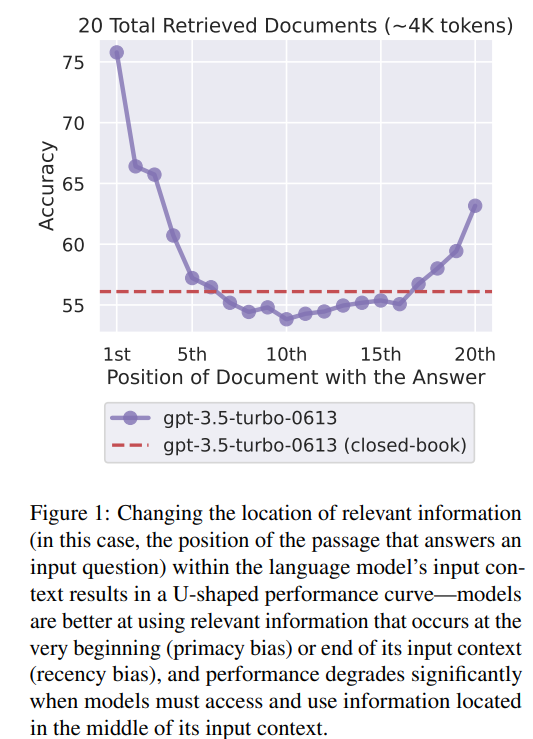
open-book - closed-book
是否允许访问外部文档。
不同模型和不同长度上下文。
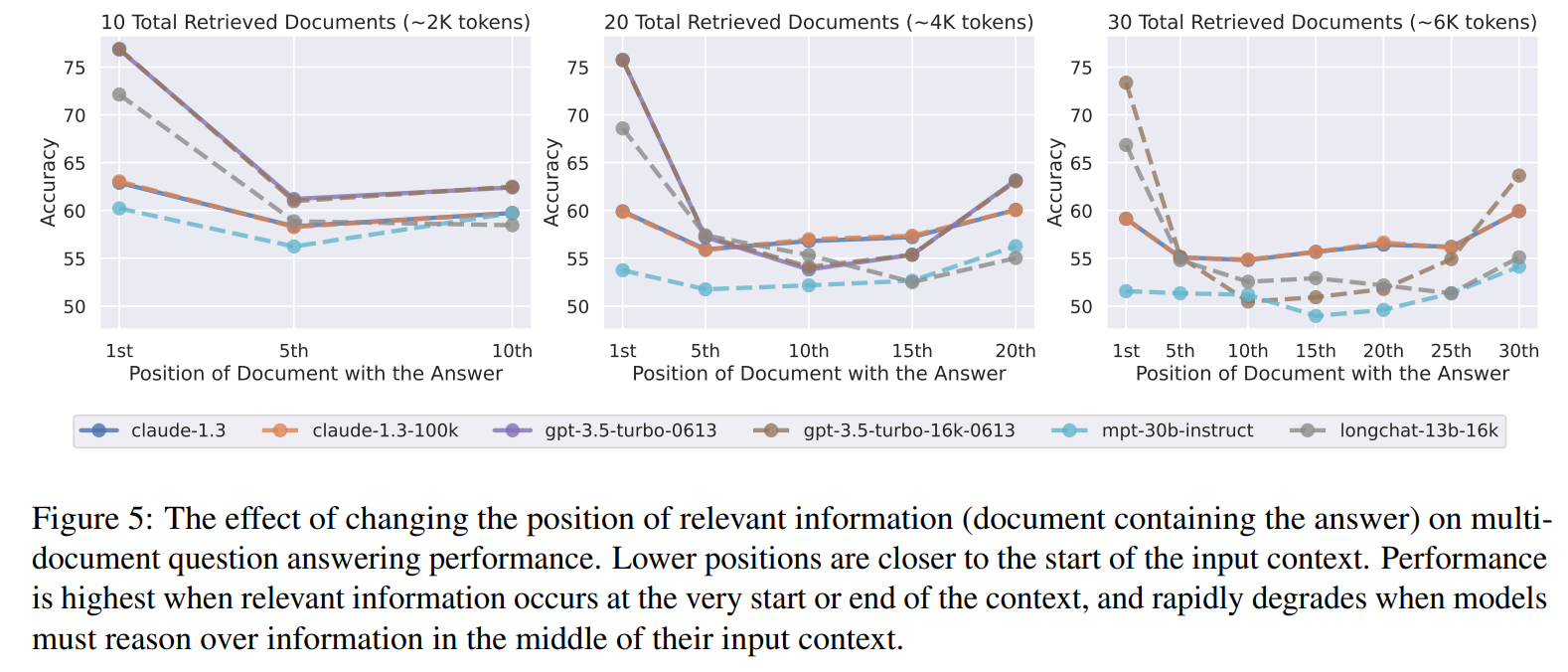
目前模型参数量会更大,上下文支持也会更大。
成因推论
架构: encoder - decoder vs decoder-only
Decoder-only 架构(如 GPT-3.5,Claude)主要用于生成任务,它们对序列的“近因”信息(Recency)天生具有更高偏好。而 Encoder-Decoder 架构(如 T5,Flan-T5)在设计上应更擅长对整个上下文进行编码和整合。
验证结果 (Figure 10):
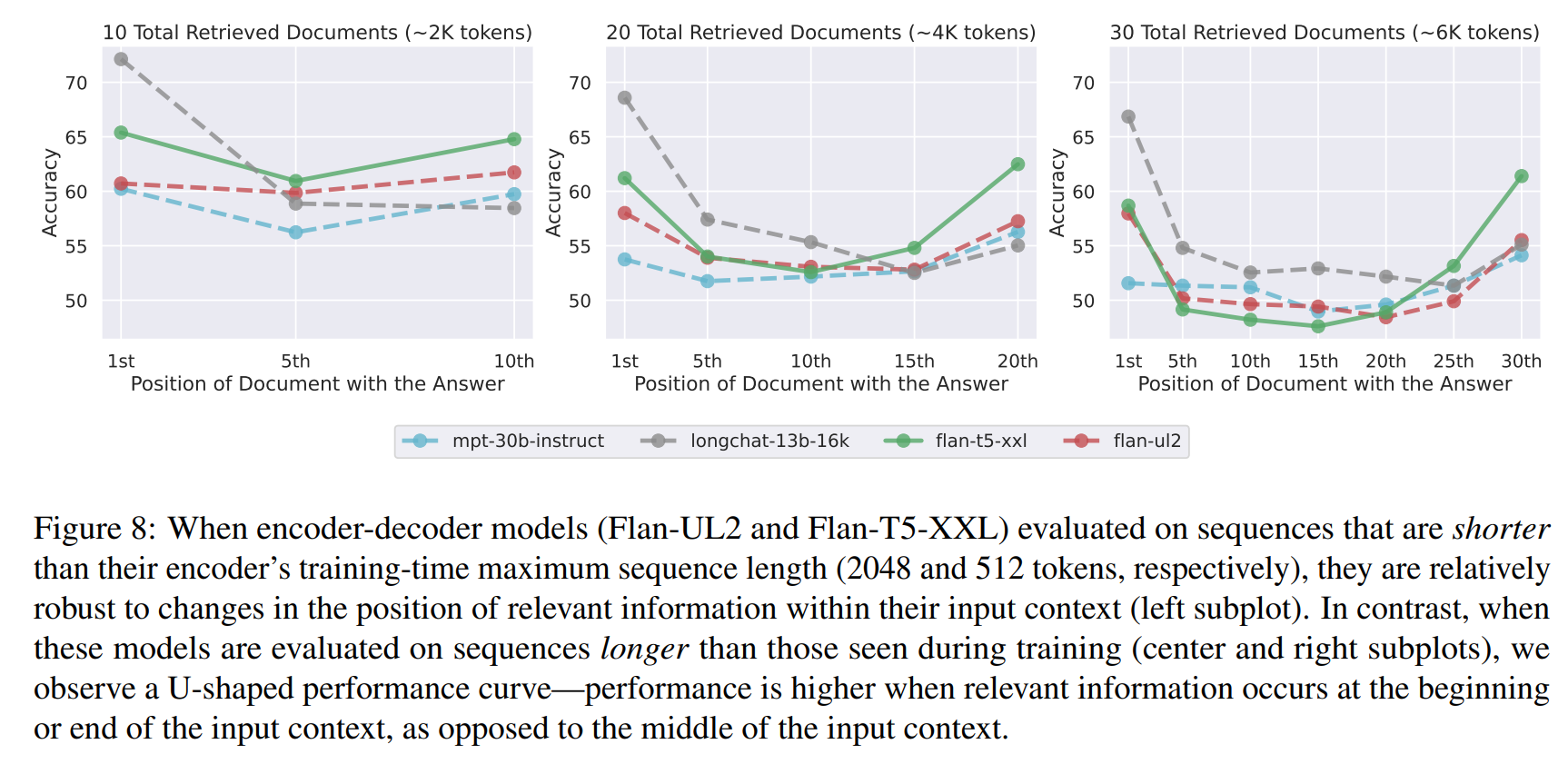
在 短上下文(例如:序列长度不超过其训练长度 2048 令牌)内,Flan-T5 表现出相对平坦的曲线,对位置变化不敏感。
但当上下文长度超出其训练窗口时,它也开始出现明显的 U 型性能下降。
是否是指令式微调带来的
理由: 在指令微调的数据集中,问题(Query)或指令总是放在上下文的开头或结尾。模型可能因此学会了只关注这些边界位置。
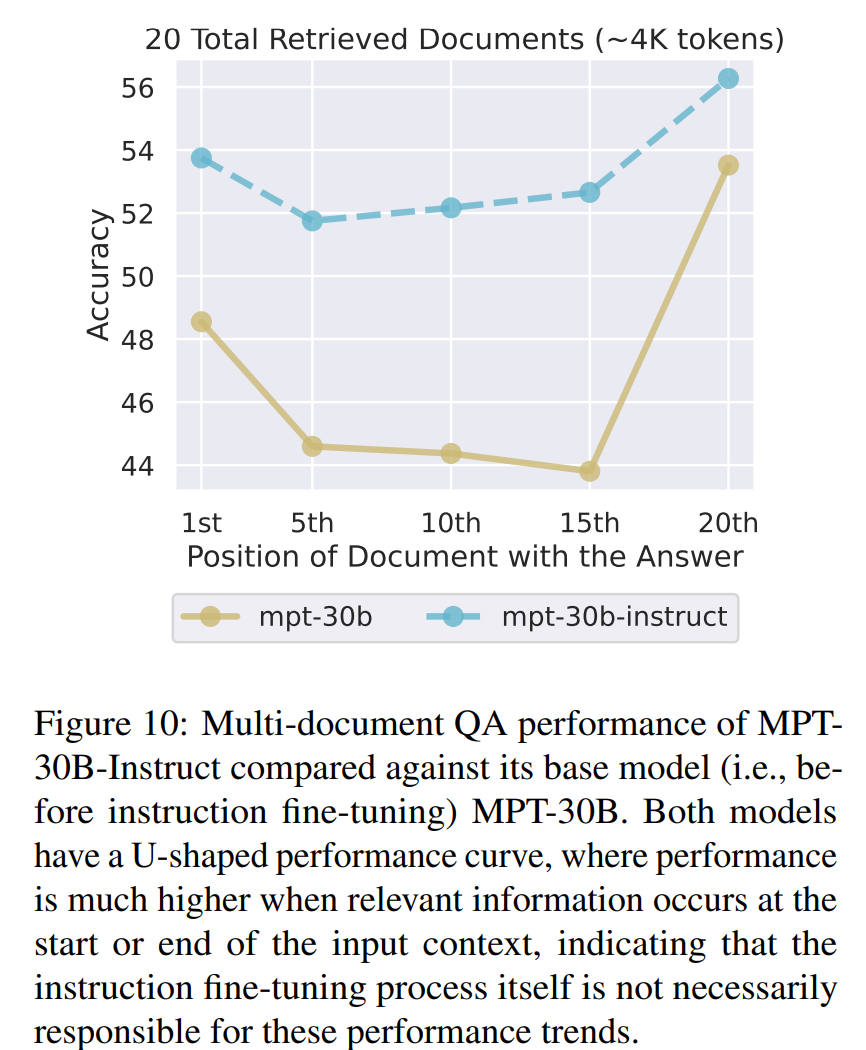
- 论文的验证方法: 比较了基础模型 (Base Model) 和经过指令微调的模型 (Instruction-Tuned Model) 在“Lost in the Middle”任务上的表现。
- 基础模型示例: MPT-30B (Base)
- 指令微调模型示例: MPT-30B-Instruct
- 验证结果 (Figure 9):
- MPT-30B (Base) 模型同样表现出明显的 U 型性能曲线。
- 论文结论:
- 这个结果表明,“Lost in the Middle”现象并非完全由指令微调引入的。
- 它更可能是一个更深层次的、在预训练阶段(Pre-training)就已经存在的问题,是 Transformer 架构本身或其长序列处理机制的固有特性。指令微调可能只是加剧了这种边界偏好,但不是它的根本原因。
能否通过结构化 prompt 修复?
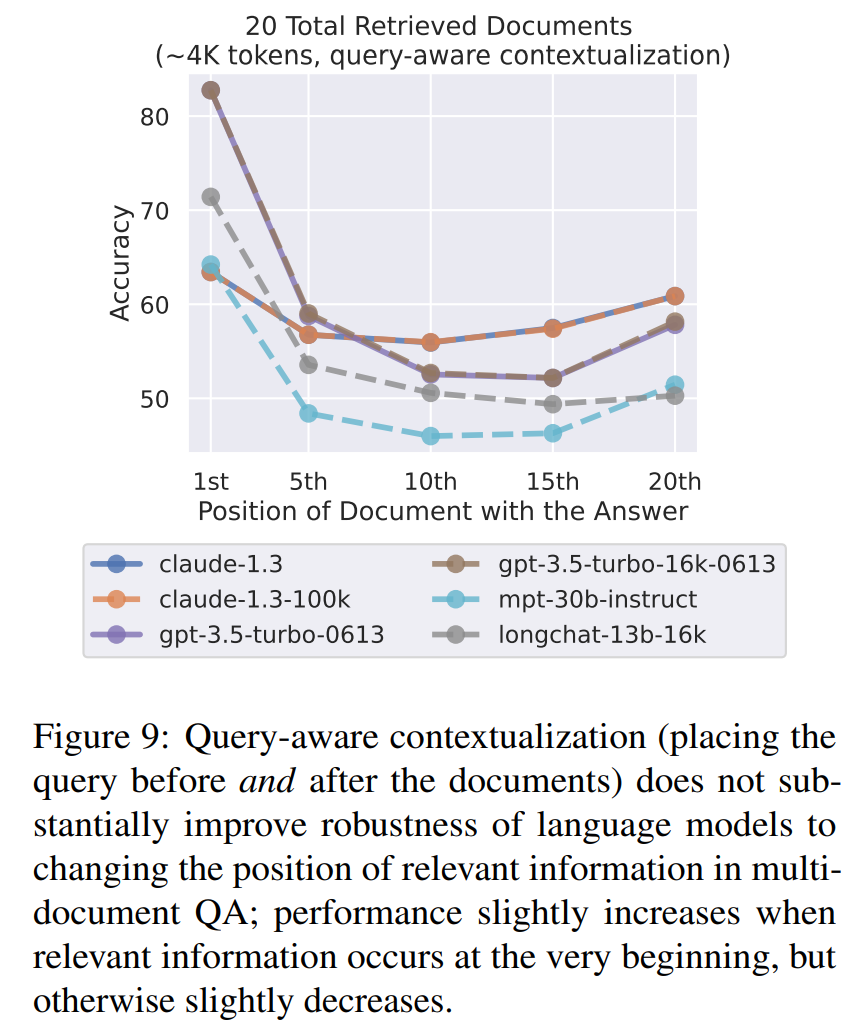
- 在上下文的开始和结束同时插入问题(
[QUERY] ... [DOCUMENTS] ... [QUERY])的效果。 - 验证结果:
- 对于简单的键值检索任务(纯粹的查找匹配),这种方法非常有效,性能几乎达到了完美,U型曲线基本消失。
- 但对于复杂的多文档问答任务(需要推理和综合),这种方法几乎没有改善,U型曲线依然存在。
我的猜想
lost in the middle 的本质是注意力分配不均且中间出现注意力空洞。
它的成因是注意力机制的本质。
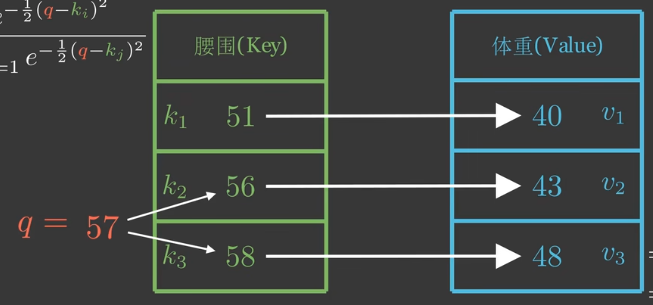
如果只看 56, 58 两行,这时候如果 query 是 57, 人会很容易地均分注意力,认为求均值就可以了,得出来体重是 45.5。
而如果加入 51 这一行,发现变化不再是均匀线性的。
那么人类会很容易地开始动态分配注意力,比如说,认为 56, 58 距离 57 更近,那么分配更高的权重 0.4, 0.4, 而 51 分配 0.2 。 这只是一个举例。
然后得到的体重是 (40/510.2+ 43/56*0.4 + 48/58*0.4) 57 = 45.3 这种分配反映了对数据不同位置的不同关注度。
而在训练的过程中,最终目的是为了降低 loss , 记住开头的信息(通常是 rules and requires) 有利于避免因为不遵守约束被惩罚, 而结尾的信息有利于结合用户需求做出最优的即时动作。
它也会不自觉地把注意力分配给两端。
它会造成什么问题?
它让 Agent Workflow 无法一直稳定运行下去。堆积的长上下文会让模型越来越笨,产生越来越多的幻觉然后罢工。
应对措施
工程实践:对于不同的 Agent 隔离上下文,并且,丢弃一次性的提示信息。比如 Tool Message 的回调。对于不需要上下文的一次性任务,在规定好人设,工作范畴后不再堆积任何上下文,每次产生的新上下文都进行 flush。
探索实践:结合 RAG 建立长短期记忆机制,建立遗忘机制。
扩展
大模型推理 - 缓存命中(KV Cache)
第一次输入(Prefill Phase): 模型并行计算所有输入词元的 和 ,并将它们存储在 GPU 内存中,即 KV Cache。 后续生成(Decoding Phase):
- 模型只计算新生成的词元的 。
- 生成新词元的 会与缓存中所有历史 计算注意力分数。
- 生成的 和 会被追加到缓存中。
这意味着在生成后续词元时,避免了对历史上下文(缓存 K,V)的重复计算
deepseek,MoE, Mixture-of-Experts(671b全参训练,37b半参推理)
- 专家路由 (Router / Gate):MoE 模型在每个 Transformer Block 中嵌入了多个并行的前馈网络(FNN),即“专家”(Experts)。
- 稀疏激活: 对于一个输入的词元,一个门控网络(Router)会学习如何评估哪个专家最适合处理这个词元。它通常只选择少数几个(例如 2 个)专家来激活并参与计算。
- 效果: 这样模型就可以在拥有巨大容量(671B)的同时,保持较低的推理成本(37B)和低延迟,实现了性能与效率的双赢。
稀疏注意力 (Sparse Attention)
核心思想: 传统的自注意力机制(Self-Attention)中,每个词元都需要与序列中的所有其他词元计算注意力分数,这导致计算复杂度为 ( 是序列长度),对于长序列是巨大的负担。稀疏注意力旨在减少不必要的注意力计算。
稀疏化策略: 稀疏注意力通过设计特定的注意力模式(Attention Pattern),使得每个词元只关注序列中的一个子集词元,而非全部词元。常见的稀疏化策略包括:
局部注意力(Local Attention): 只关注自身周围一个固定大小窗口内的词元。
跨步注意力(Strided Attention): 隔固定步长关注词元。
全局注意力(Global Attention): 选择少量特殊词元(如
[CLS]或[SEP])与所有词元互相关注,以捕捉全局信息。
效果: 将计算复杂度从 降低到接近 (或 ),显著降低了长序列的计算和内存开销,使得模型能够处理更长的上下文。
被问住的问题
我自己是想不到有什么问题可以问的,但是确实老师就把我给问住了。相比同学的提问,老师问的几个问题都精准抓到了我不那么懂的点。
论文本身和人机协作与混合系统无关。
...
这点是我的锅。
因为我通常思路比较奇怪,我第一眼看到这篇文章就觉得它和 LLM-Agent-Workflow 关系会非常大。
但是,确实,论文本身没有提及任何人机协作和混合系统,所有相关内容都是我脑补和拓展出来的。
上下文上限具体指什么,与参数量有什么关系,如何判断是否达到上限, token 怎么算?
因为我提到了,上下文上限和模型参数量不一定直接相关,比如 gemini-2.5 是 1000k, 而 claude-3.5-sonnet 是 500k, deepseek-r1 是 128k,但是模型参数量不一定 gemini 最大, 而且 gemini不一定比 claude强,deepseek-r1 的 moe 架构也会造成影响。
这块还得问下 gemini(doge)。
定义
上下文上限(也常被称为“上下文窗口”)指的是一个大语言模型在一次交互中能够“看到”和“处理”的最大信息量。
包含内容: 这个“信息量”同时包括:
- 你的输入(Prompt): 你提的问题、给的指令、上传的文档、聊天历史记录等。
- 模型的输出(Response): 模型生成和回答的内容。
现在应该还包括 Tool Response 等等。
- 计量单位: 这个上限通常用 Token 来衡量。
上下文上限与参数量关系
上下文上限和模型参数量没有直接的、线性的正比关系。
参数量 (Parameter Count):
- 是什么: 模型中所有“权重”(weights)和“偏置”(biases)的总数。
- 代表什么: 更像模型的知识存储量和推理复杂度。参数量越大,模型在训练时“记住”的知识和模式就越多,理论上“更聪明”。(可以粗略理解为“大脑的容量”)
- 影响: 主要影响模型的通用能力、知识广度和推理深度。
上下文窗口 (Context Window):
- 是什么: 模型的架构设计(特别是注意力机制)和训练方法共同决定的一个属性。
- 代表什么: 代表模型一次能处理多少信息。(可以粗略理解为“大脑的瞬时记忆”或“工作台的面积”)
- 影响: 主要影响模型处理长文本、多轮对话、复杂指令和文档分析的能力。
我刚刚修正了超出上下文的内容。
我以前有好几个误解。
第一个是,超出上下文模型会直接罢工,开摆,让你新开对话,而不是性能下降。
第二个是 U 型出现的位置,现在的大模型很多不会看到全部的上下文,因为上下文窗口真的太长了,在实际使用的时候他可能会截断。
动态分配 U 型是在他能看到的上下文上限之内。
gemini 就是截断的 32k (日常使用 64 轮左右,每轮 300 ~ 500 字符)。 而 deepseek-r1 是无截断的。超出直接让你开新对话。
那么对于 gemini, 它分配 U 型也是在这 32k 之内,另外由于 32k 远在它的能力范围(1000k)之内,所以它的 U 型会很浅。
token 怎么算?
输入 token 和输出 token 。 看 tokenizer, 英文单词:token比大概 1:1, 中文字符 : token 比大概 1.5:1。中文的 token 信息量是要低于英文的。
怎么看超不超出上下文。
有截断的上下文现在已经不会超上下文了。而无截断的比如 deepseek-r1 它让你重开对话的时候就是超了。
至于 U 型曲线的结论最后应该修正为: 在模型最大能处理的上下文上限内,越接近这个上限,模型的 U 型越严重。
所以很好理解为什么 gpt-3.5-turbo 16k 在 20 ~ 30 轮的时候 U 型严重。
如果不事先知道被截断这一点,那么这个实验是无法被复现的,1000k 只用了 32k , 而且模型能力很强,根本无法复现那么明显的 U 型。
论文中对于多文档问答的答案验证是相似度匹配还是人为判断?
Following Kandpal et al. (2022) and Mallen et al. (2023), we use accuracy as our primary evaluation metric, judging whether any of the correct answers (as taken from the Natural Questions annotations) appear in the predicted output.
论文里提到了它采用了和前两者(Kandpal et al. (2022) and Mallen et al. (2023),)一样的方式。这个方式似乎是和数据集标注相关的。
但前两者 =-=
似乎是相似度匹配。判断正确答案是否出现在模型输出中
在最后的最后。
关于 Lost in the middle, 我的认知历程相当复杂。
从最初的一点小建议,到后来的 Attention is limmited,再到 序列位置效应。
最后再到我们目前这个版本。
包括这个版本也更正了一次。
在我讲完内容被提问后,我发现我的理解里有非常非常多的漏洞,然后现在被补上了。
而是否每次都需要这么深入地,找论据,找论文,说实话,这么多,非常曲折,而且也累,还得有机会,比如我给两个人讲过,然后修正了一部分,又在班上讲了一次,又修正了一次。即使,现在,我觉得又没什么好问的,没什么可改的,当然可能这个总结可能遗留有些没修正。但我在逻辑上又自洽了,又自己舒服起来了,除非有人再打破我的这个逻辑,不然还真没法更深入。
深入以后,看起来也更累。属于我自己都懒得再看那种。
而,如果只是停留在,大模型给一个 Best Practice, 简单告诉你,噢你应该这么做,因为它符合黄金 rule 。我在使用的时候也会非常疑惑。这种疑惑在我日常 Python 调包的时候偶尔侵袭我。
按照日常来说,我应该只需要做到 Attention is limitied 那层就可以了。当然,在挑论文的时候得防止被无法复现的水文给坑了。
在此搁笔。