Lost in the middle 后续与 RAG 记忆系统调研
Lost in the Middle
Lost in the Middle 发布之后已经过了很久。
我前阵子写了这个:
Lost in the middle - how it affect LLM agent system
里面还有不少说法经不起推敲,因为来源不太可靠。
但可以定下来的是:
Lost in the Middle 前置概念
我会分成结论+证据的形式来写。
- 大模型在接受输入时会把当前用户输入加到整个历史上下文中然后进行推理,而不是仅仅对当前输入和提问进行推理。所以上下文越长,token 消耗费用越高,两者线性相关。
我说的这个情况是针对于 Stateless LLM, Gemini-2.5, OpenAI-5.2 等等常在 API 中使用的模型都是 Stateless LLM。它的特征是每次文本生成请求是独立且无状态。所以如果要实现连续对话都要手动创建一个列表把之前的历史对话加进去。(当然并不代表每次都要从 0 计算,具体参见下方)
While each text generation request is independent and stateless, you can still implement multi-turn conversations by providing additional messages as parameters to your text generation request. OpenAI Conversation State
当然,这里也许只能说明 API 调用时每次输入都需要完整输入,不能完全说明模型每次推理时一定要所有的输入。(因为这看上去是复用率很低的一个做法。)
但事实是,这正是 LLM 的底层计算逻辑,或者说由于底层的 Transformer,所有的 token ~ 会被作为 ~ 的计算条件。
The prompt phase takes the whole user prompt (𝑥1, . . . , 𝑥𝑛) as input and computes the probability of the first new token 𝑃 (𝑥𝑛+1 | 𝑥1, . . . , 𝑥𝑛).
Efficient Memory Management for Large Language Model Serving with PagedAttention
但实际上虽然模型每次输入都是整个上下文,但并不是每次都从 0 计算。 KV-cache 是很好的例子,它减少了重复计算带来的计算量。
At iteration 𝑡, the model takes one token 𝑥𝑛+𝑡 as input and computes the probability 𝑃 (𝑥𝑛+𝑡+1 | 𝑥1, . . . , 𝑥𝑛+𝑡) with the key vectors 𝑘1, . . . , 𝑘𝑛+𝑡 and value vectors𝑣1, . . . , 𝑣𝑛+𝑡 . Note that the key and value vectors at positions 1 to 𝑛 + 𝑡 − 1 are cached at previous iterations, only the new key and value vector 𝑘𝑛+𝑡 and 𝑣𝑛+𝑡 are computed at this iteration.
Efficient Memory Management for Large Language Model Serving with PagedAttention
- 计量上下文窗口上限的单位是 token,判断是否超出上限是看单次请求中模型能共同理解的输入+输出 token 总量上限,所以简单来说可以细分为输入超上限,和输出超上限,但两者表现出来的结果没什么。
上下文窗口(context window)是单次请求中模型能处理的 token 总量上限。
对 OpenAI 的一些模型/接口表述来说,这个上限明确包含:input tokens + output tokens + reasoning tokens。
The context window is the maximum number of tokens that can be used in a single request.
This max tokens number includes input, output, and reasoning tokens.
Conversation state
另外早期对于单次提示词输入的上限一般也有一些暴力约束比如单次输入 < 10000字。但大模型是并没有推理时一般并没有这方面的直接约束。
超过上下文窗口时,要么请求失败(API/模型直接报错),要么系统只保留/压缩/忽略一部分上下文,导致回复不再覆盖全部内容。
这里是 OpenAI API 在碰到超出上下文时给用户的truncation策略,可以自行选择。
auto: If the input to this Response exceeds the model's context window size, the model will truncate the response to fit the context window by dropping items from the beginning of the conversation.disabled(default): If the input size will exceed the context window size for a model, the request will fail with a 400 error.
OpenAI Responses
- 越接近上下文上限,模型的 U 形曲线特征越明显, Lost in the middle 越严重。
以及关于 Lost in the Middle 概念的一些详细内容我也曾写过。
Lost in the middle - how it affect LLM agent system
Lost in the Middle 是否依然存在于近期的语言模型
之后是目前真正关心的,是 Lost in the Middle 的现象,在最近的 LLM 中是否被解决。
当时我的推断是并未被解决,因为 LLM 的底层并没有变化。但目前需要来找些证据。
关于 Lost in the Middle (以下简称 LITM)的现象,我找到了这些相关内容:
- LongBench v2: 长语境、多任务下模型的推理理解能力评分 : Gemini-2.5 Flash, GLM-4.5 等等最近一年的无思维链推理的模型在 zero-shot without COT (零样本,无外接数据库或者搜索引擎;无思维链)的方式中上,由 Short -> Long 跳跃时,准确率掉了很多。
说明长文本对于目前模型的性能表现依然影响很大,虽然不能断言这个时由于 LITM 的现象,因为这里体现的是长度效应。而 LITM 则是位置效应。
另外这里比较好奇的一点是,具有思维链(CoT)的模型在文本变长时,有时性能不降反增,这很有意思。
经过查阅,得知 CoT 模型之所以在任务准确率上有提高是因为是会减少“猜测式”输出与格式错误。并不是根本上解决了长度效应(提高理解能力)。这就好像一场考试里, without CoT 的学生只有 120 分钟,且所有问题只做了一遍就交卷,以及它还有自己的草稿纸(CoT),可以分步拆解问题,而 CoT 的时间上更充裕,可以反复地检查自己是否有一些粗心犯错。
- # \inftyBench: Extending Long Context Evaluation Beyond 100K Tokens: 很多模型/系统“能吃进去”100K/200K tokens(标称窗口),但在真实任务里“用得起来”的信息量(有效上下文)明显更小;当长度继续拉长,性能会退化。
他们提出了一个有效窗口的概念,有的大模型即使声称可以接受 100/200k tokens 或者 1M tokens,但是实际的消融实验中,当上下文长度越长,性能表现越糟糕。
另外在 5.2 部分我看到他们提到了 Lost in the Middle。

image-20260102161101092
这里是他们做的位置效应的图:
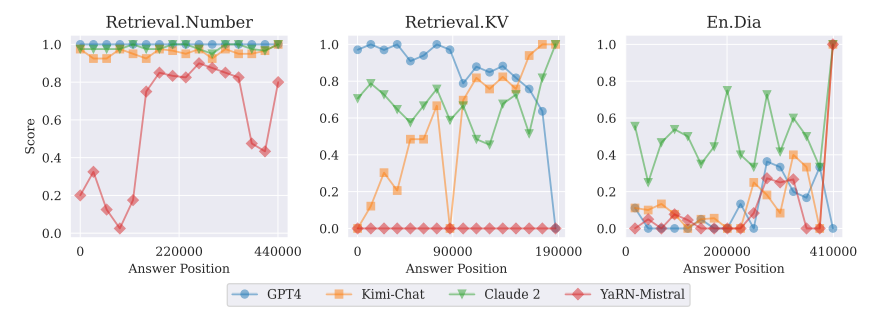
image-20260102161154099
这里他们发现,对于不同产商的大模型,他们并没有在位置效应上呈现一致性。有的偏向首因,有的偏向中间。
这点看起来似乎否定了目前 Lost in the Middle 现象的存在。
但是我个人抱持的观点是,Lost in the Middle 中提到的 Transformer 预训练时存在的问题还未解决,只是在不同的应对方式下变成了不同的表现方式。
并且我在之后找到了可以支撑我观点的有效实验,即这个位置效应导致的注意力结构性偏差依然存在。
“strong attention scores towards initial tokens as a ‘sink’ even if they are not semantically important.” arXiv
翻译: 模型会对最初的 token给出很强的注意力分数,把它们当成“汇点(sink)”,即使这些 token 在语义上并不重要。
“attention sinks exist universally in LMs … even in small models.” arXiv
翻译: 注意力汇点在各种语言模型中普遍存在,甚至在小模型里也存在。
“attention sink is observed to emerge during the LM pre-training.” arXiv
翻译: 注意力汇点被观察到会在语言模型预训练过程中出现。
这里对模型的注意力结构性偏差进行了一些追踪和研究。并且发现了它在各种语言模型中普遍存在,且出现在预训练的过程中。
这可以说是 LITM 的一次溯源和解释,至少 Primacy Effect 是找到了。
“even when … trained … struggle to capture relevant information … in the middle.” arXiv
即使模型被专门训练来处理长输入上下文,仍然难以捕捉位于输入中间的相关信息。
“mitigate this positional bias through a calibration mechanism, found-in-the-middle.” arXiv
他们通过一种校准机制(found-in-the-middle)来缓解这种位置偏置。
这篇论文发现 LITM 始终存在,并且研究了一些缓解策略,当然这缓解策略肯定并不能治本,毕竟问题出现在更早的阶段。当然这也可能是为什么各大产商的位置效应表现得各不相同,缓解的方式不同。
如果有完全解决预训练阶段的注意力位置偏差的方法,那应当是一篇集体引用的颠覆性的论文,但目前是还未出现的。
记忆系统 RAG 调研
上面的所有工作总结起来就是: LITM 依然存在,且 LITM 目前在不同产商大模型中以不同的方式存在,不再只是呈现出 U 形。
那么,我们的记忆系统应该怎么做?(你可能会觉得有点突兀,但是我扯那么多确实是为了我的记忆系统。)
相比于 LITM 那边学术氛围会更重, RAG 这边更偏工程。所以对于论文的引用不会像之前那么多。因为比起论文的“我还有什么”,工程这边更在在意“我能用我现在的东西做什么”。
这里是我的一些灵感来源:
关于酒馆SillyTavern所代表的伴侣模型系统的一些小思考
这里是已有的发表的一些研究:
贪多嚼不烂,我们就先以 MemGPT 为重心,它提出来的相当多设计在我的系统中也依然使用着。
MemGPT
1.MemGPT 要解决的核心问题是什么
LLM 固定上下文窗口导致两类典型失败场景:
长期对话:跨会话一致性差、忘记用户偏好/事实、无法形成长期关系
超长文档分析:文档远超 context window,关键信息“进不来/留不住/用不上”
MemGPT 的核心主张是:
不追求把所有历史都塞进 prompt,而是让模型“像操作系统一样”在有限窗口里 动态调度信息
另外,这里可以回忆下前面的内容:
- 超过上下文窗口时,要么请求失败(API/模型直接报错),要么系统只保留/压缩/忽略一部分上下文,导致回复不再覆盖全部内容。
- # \inftyBench: Extending Long Context Evaluation Beyond 100K Tokens: 很多模型/系统“能吃进去”100K/200K tokens(标称窗口),但在真实任务里“用得起来”的信息量(有效上下文)明显更小;当长度继续拉长,性能会退化。
所以 MemGPT 的核心问题现在也依然是核心,它仍然很具参考价值。
2. 架构总览:把 LLM 当“CPU”,把上下文当“主存”,把外置数据库作为”外存“
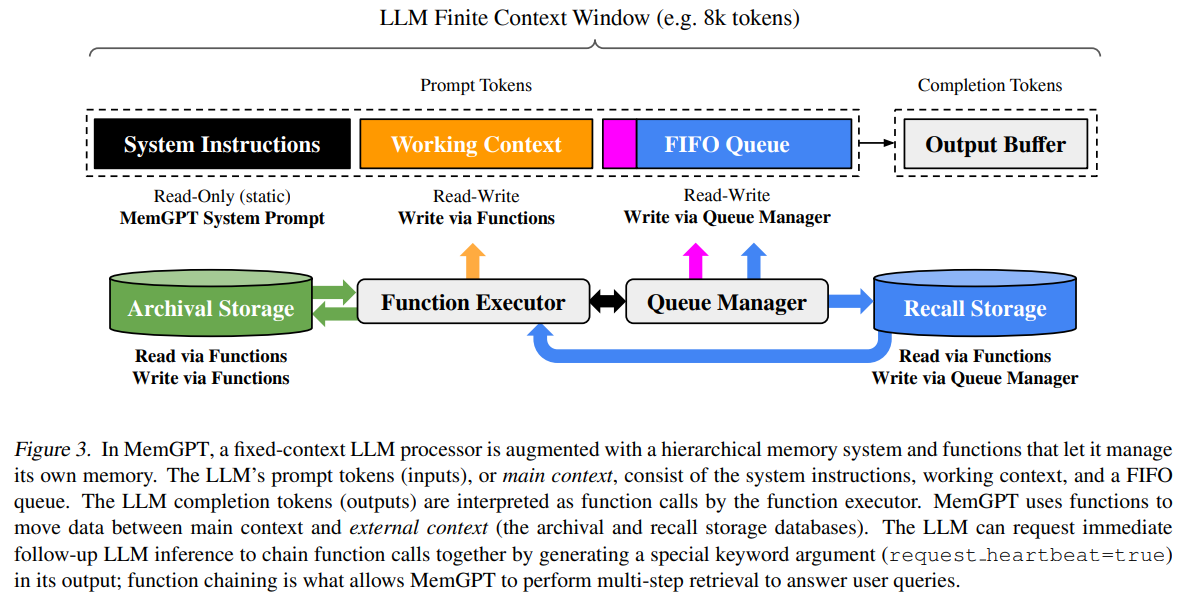
MemGPT 的系统架构图
图 3。 在 MemGPT 中,一个固定上下文的 LLM 处理器被一个分层记忆系统以及一组允许它管理自身记忆的函数所增强。LLM 的提示词 token(输入),也就是主上下文,由系统指令、工作上下文和一个 FIFO 队列组成。LLM 的补全 token(输出)会被函数执行器解释为函数调用。MemGPT 使用这些函数在主上下文与外部上下文(归档存储与回忆存储两个数据库)之间移动数据。LLM 还可以通过在输出中生成一个特殊的关键字参数(request heartbeat=true)来请求立即进行后续的 LLM 推理,以便把多个函数调用串联起来;这种函数链式调用使 MemGPT 能够执行多步检索,从而回答用户查询。
为什么要对上下文分区块
对于 Prompt Tokens 的内容很好理解,就是模型的上下文,不过被区分成了几块,至于为什么区分在现在是很好理解的。
比如用 MCP 调用外部工具的模型,它的上下文中会包含这样的步骤:
User: 今天的天气怎么样?
Assitant:[require_search_for_weather]
User: Call Tool require_search_for_weather
Tool: sunny
User:[User:今天的天气怎么样,Tool:Sunny]
Assitant: 今天是晴天。
在用户问”今天的天气怎么样?“并且触发 MCP 的时候实际上中间还至少包含了一个 Function Call 的回复【或者说它一直在,只是有时 True 有时 False】和 Tool Message 的回复,以及把 Tool Message 和用户问题再次发给模型的过程。这个过程按照逻辑理解,应该是 system 来提供,但是 system 的空间更金贵,而且容易稀释注意力和引起冲突幻觉,所以一般整个过程都以 role = "user" 来进行。
而这个过程中,不少上下文在结果产生后都是多余的,最终为了保持干净工作区和上下文一般都会选择只保留:
User: 今天的天气怎么样?
Assitant: 今天是晴天。
这也是工作区中 Read-Write 的意义所在,上下文是可以编辑的,可以控制有效上下文的长度,隔离一些用过一次后就不会再用的信息,可以让模型性能衰减变慢。
不过这里 MemGPT 的 Function Call 应该是 Based-Prompt 而非模型原生支持的(微调出来的)。
这里分区块把原本的上下文切割隔离成了三段,对于上下文管理来说是很好的,同时它还为三段分别设置了不同的写入权限和写入方式,我之前也搞过上下文管理,但是没有区分权限有时候就会很难处理。这点启发颇多。
我不会照着原文读,那真的很无聊,我会很多地方进行类比推论。而且,我可能不一定会验证,如果我能说服自己,可能会让模型验证一下。
MemGPT 工作区中各个区块的具体功能
首先这些区块共同组成了我们所认识那个上下文,它只是做了不同权限和方式的写入读取方式,这点很有意思。
System Instructions
不可修改。
我最早以为这应该是系统提示词,人设之类的,但并不全是这样。
它的这个 "System" 的意思是操作系统,它以提示词的方式书写了控制流,各个内存区块用途,包含哪些函数,函数用法说明。这就像什么,像系统内核。它给 LLM 洗脑,告诉它是一个操作系统,具有哪些基础命令、资源等等。这是手动实现 Function Call 的核心,但是这个成功率估计非常感人,还和底座模型的理解能力强挂钩。
各种猎奇人设见了不少,人机 play 是第一次见。这个模型先记住了自己是个操作系统,然后才是各种人设。
Working Context
固定大小的一段窗口,只能通过特定函数来写,存关键事实、偏好、智能体人设。
有点像一个小型的数据库,不过一直在而不是等待检索,存放一些关键信息。
FIFO queue
滚动消息历史。
这一块才是我们正常使用上下文的方式,把对话一条一条按顺序存入,滚动。
它加了什么:
这是一个队列,长度也是固定,当临近队满的时候会开始写入外部的数据库(Recall、Archival Storage,模型自行决策)。
队列首部还有一个递归概要,概括被逐出队列的更早的消息。
待续。